聚簇索引 & 非聚簇索引
1. 什么是聚簇索引(Clustered Index)
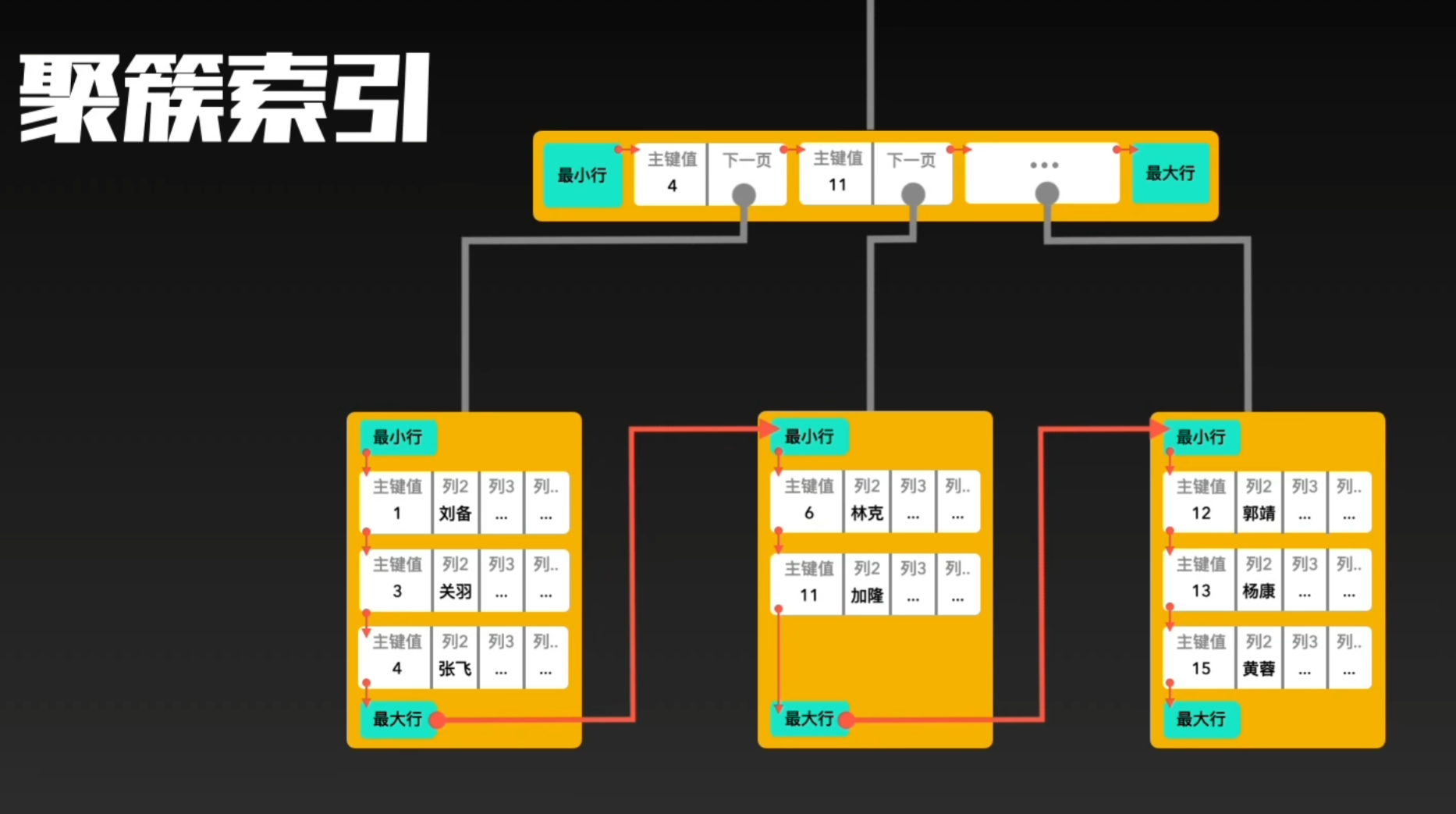
Section titled “1. 什么是聚簇索引(Clustered Index)”在 MySQL 的 InnoDB 存储引擎中,聚簇索引也称为聚集索引或一级索引,它既是索引目录,同时也是存储数据的结构。聚簇索引使用 B+ 树 组织数据,其中叶子节点存储每一行的完整数据,而非叶子节点仅存储索引键(Key)作为导航目录,用于快速定位叶子节点。
每张 InnoDB 表最多只能有一个聚簇索引。通常情况下,聚簇索引以表的 主键(Primary Key) 作为索引键构建。如果表没有主键,InnoDB 会选择第一个唯一索引(UNIQUE)列来构建聚簇索引;如果连唯一索引也没有,InnoDB 会生成一个隐藏的 6 字节自增列,用于构建聚簇索引,保证表中每行数据的唯一性。
当查询是基于主键进行时,数据库会通过聚簇索引的非叶子节点快速定位叶子节点,从而直接获取完整的行数据,无需再进行回表操作。这种设计使得主键查询在 InnoDB 中非常高效,同时也保证了数据的有序存储,尤其是当主键是自增 ID 时,插入操作几乎是顺序写入,进一步提高了性能。
总的来说,聚簇索引的特点可以概括为:叶子节点存整行数据,非叶子节点存索引键;表中最多只有一个聚簇索引,优先使用主键,其次唯一索引,再无则生成隐藏列;主键查询无需回表,性能高且数据有序。
对于二级索引而言,InnoDB 存储的是主键值,递增主键意味着二级索引的插入和维护也相对顺序,减少了随机 I/O,维护成本更低。同时,递增主键保证了数据的有序性,对于范围查询(如 WHERE id BETWEEN x AND y)非常高效,而随机主键无法保证顺序,范围查询可能需要访问大量不连续的数据页,性能差。
综合来看,自增或递增主键能够带来顺序写入、减少页分裂、提高缓存命中、降低二级索引维护成本以及优化范围查询等多个性能优势,因此在大多数 MySQL 表设计中被推荐使用。
此外,递增主键还能提高缓存的利用率。顺序插入的数据在 Buffer Pool 中的访问局部性更好,缓存命中率高,而随机主键可能频繁访问不同页,导致缓存利用效率下降。对于二级索引而言,InnoDB 存储的是主键值,递增主键意味着二级索引的插入和维护也相对顺序,减少了随机 I/O,维护成本更低。同时,递增主键保证了数据的有序性,对于范围查询(如 WHERE id BETWEEN x AND y)非常高效,而随机主键无法保证顺序,范围查询可能需要访问大量不连续的数据页,性能差。
综合来看,自增或递增主键能够带来顺序写入、减少页分裂、提高缓存命中、降低二级索引维护成本以及优化范围查询等多个性能优势,因此在大多数 MySQL 表设计中被推荐使用。
2. 什么是非聚簇索引(Secondary Index)
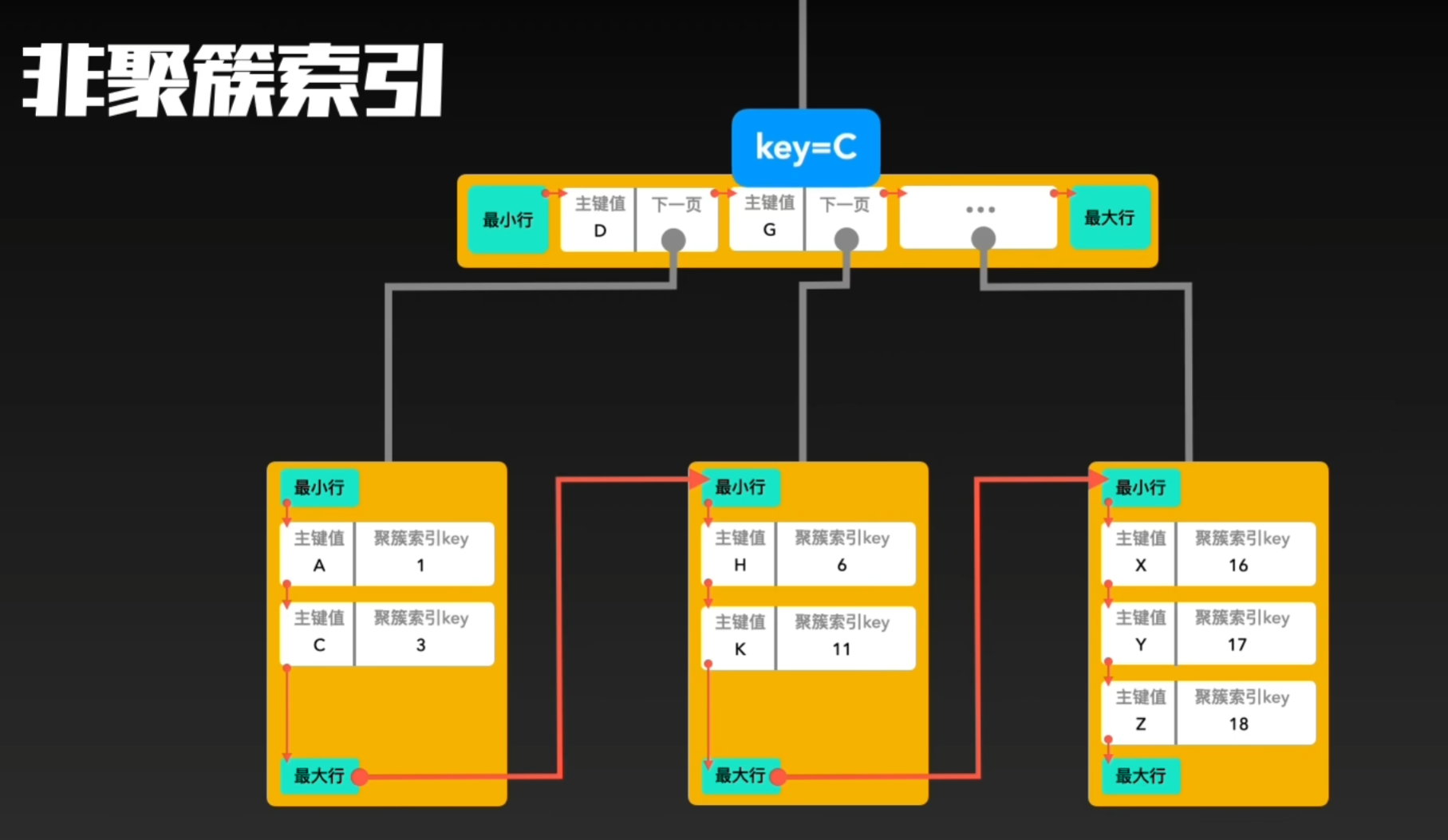
Section titled “2. 什么是非聚簇索引(Secondary Index)”在 MySQL 的 InnoDB 存储引擎中,非聚簇索引也被称为辅助索引或二级索引。它指的是除了聚簇索引(主键索引)之外的其他索引,每一个非聚簇索引都会构建一棵独立的 B+ 树。与聚簇索引不同,非聚簇索引的叶子节点并不存储整行数据,而是存储 索引列的值以及对应行的主键 key。非叶子节点只存储索引列,用作导航目录,快速定位叶子节点。
需要注意的是,如果表的主键很长,二级索引叶子节点中存储的主键 key 也会随之变长,从而占用更多的存储空间。因此在设计主键时,应考虑对二级索引空间的影响。
在使用二级索引进行查询时,MySQL 的流程如下:首先通过非叶子节点快速找到叶子节点,然后从叶子节点获取对应行的主键 key,接着再回到聚簇索引中查找整行数据。这一过程被称为 回表(Lookup)。由于二级索引叶子节点不存整行数据,因此任何需要返回完整行的查询,都会经历这个回表操作。
总结来说,非聚簇索引的核心特点是:叶子节点存 索引列 + 主键 key,非叶子节点存 索引列;查询二级索引时通常需要回表获取整行数据;主键越长,二级索引占用空间越多。它的设计让非主键列的查询也能高效定位行,同时保持聚簇索引叶子节点的数据完整性。
| 特性 | 聚簇索引 | 非聚簇索引(辅助索引/二级索引) |
|---|---|---|
| 叶子节点 | 存储整行数据 | 存储索引列 + 主键 key |
| 非叶子节点 | 存储索引键 | 存储索引列 |
| 数量限制 | 每表最多 1 个 | 每表可有多个 |
| 查询效率 | 主键查询无需回表,直接获取整行数据 | 查询需回表获取整行数据(覆盖索引除外) |
| 主键长度影响 | 无 | 主键越长,占用空间越大 |
